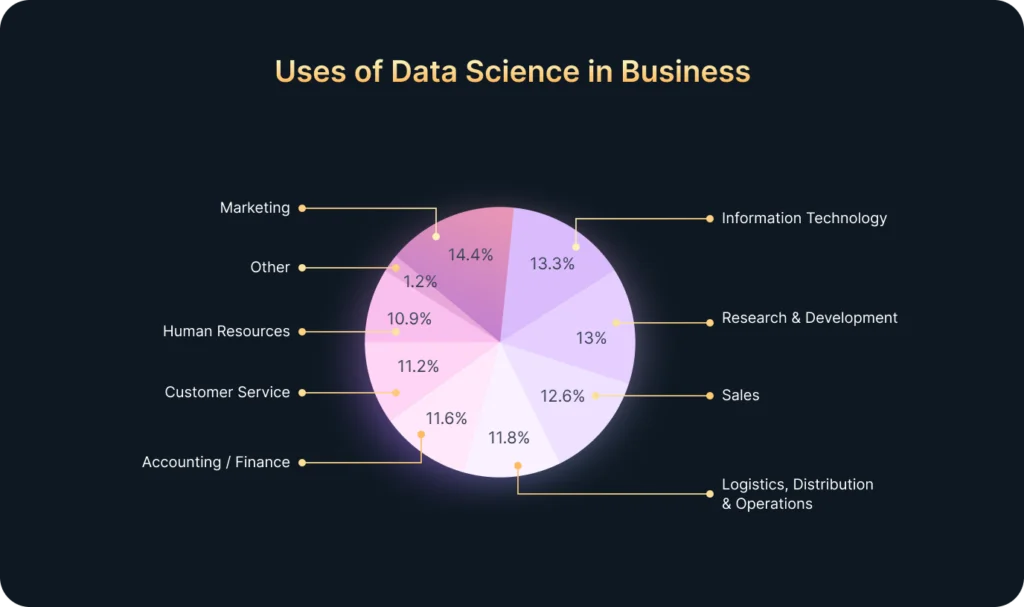
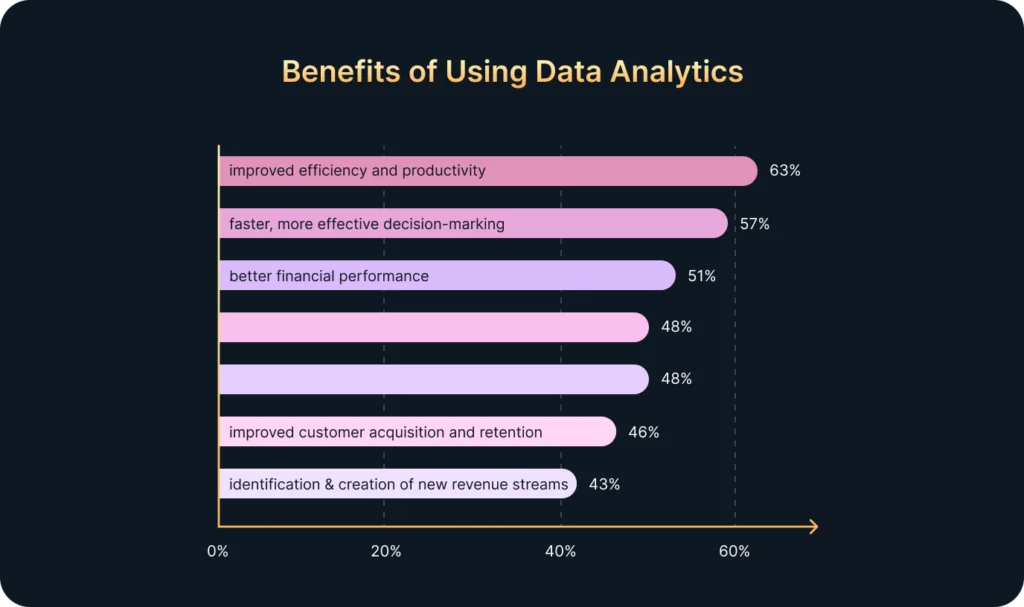
Big data is losing momentum and becoming less and less relevant. But what will supersede it?
The past decade has been defined by the importance of Big Data. It has powered marketing and financial forecasting, enabled the development of modern LLMs and generative AI models, and has even been involved in the design of security architectures. At first glance, the logic is straightforward: the more data you have, the more insights you can extract, right?
However, over time, several critical issues of Big Data have emerged.
Firstly, data comes at a cost, and at scale, that cost becomes significant.
Secondly, even data that seems to be an infinite resource can become constrained, especially when your development requires high-quality, legally compliant, human-generated training data.
Finally, recent research suggests that more does not necessarily mean better. In many cases, smaller, well-structured datasets can outperform bulky, unstructured Big Data, while also reducing bias.
So, in today’s blog, I’ll share insights into Small Data and synthetic data, two approaches increasingly adopted in modern data science, which, to my mind, are already rapidly gaining traction and may potentially be better investment choices.
The End of “More Is Better”?
During the early stages of AI adoption, it was widely assumed that vast amounts of data were required to develop language models. To some extent, this assumption proved valid. Major players such as OpenAI and Anthropic did indeed benefit from training their models on Big Data. As a result, these models became capable of handling complex tasks such as coding or analyzing clinical research.
However, maintaining output quality at scale has become increasingly challenging. Large datasets often introduce noise, redundancy, and bias, which negatively affect model performance due to poor data quality management. Moreover, maintaining these systems in production requires significant computational and financial resources. Thus, Big Data is not always the optimal approach, especially for niche or domain-specific solutions, where precision outweighs quantity.
To illustrate this point, consider one of our recent projects delivered as part of our data science engagements. We were tasked with developing a solution to predict occupancy levels at locations. Initially, we worked with a large, unstructured dataset, which led to inaccuracies. However, once we shifted our approach to focus on smaller, well-structured data, the model’s performance improved significantly. This case clearly demonstrates that more data does not necessarily mean better outcomes. Today, higher-quality data equals higher efficiency.
Small Data, Big Impact
Traditionally, extracting meaningful insights for AI training, forecasting, or database development relied on processing large-scale datasets. However, over time, a shift has emerged toward smaller, structured, and domain-specific datasets. These datasets can be analyzed effectively with fewer observations, significantly reducing both projects’ time and costs. Additionally, smaller datasets enable the development of more precise, tailored, and domain-aware solutions. The modern tech landscape is increasingly focused on sourcing accessible, expert-curated, structured, and interconnected data, giving rise to the concept known as Small Data.
Small Data consists of targeted datasets that focus on specific aspects of a problem domain. Unlike Big Data, which prioritizes scale, Small Data emphasizes quality and relevance, delivering insights that are easier to interpret and directly applicable to decision-making. Also, the key difference between Big Data and Small Data usages lies in their analytical focus:
– Big Data is primarily used to identify patterns and correlations across massive datasets
– Small Data is used to uncover causal relationships and underlying drivers
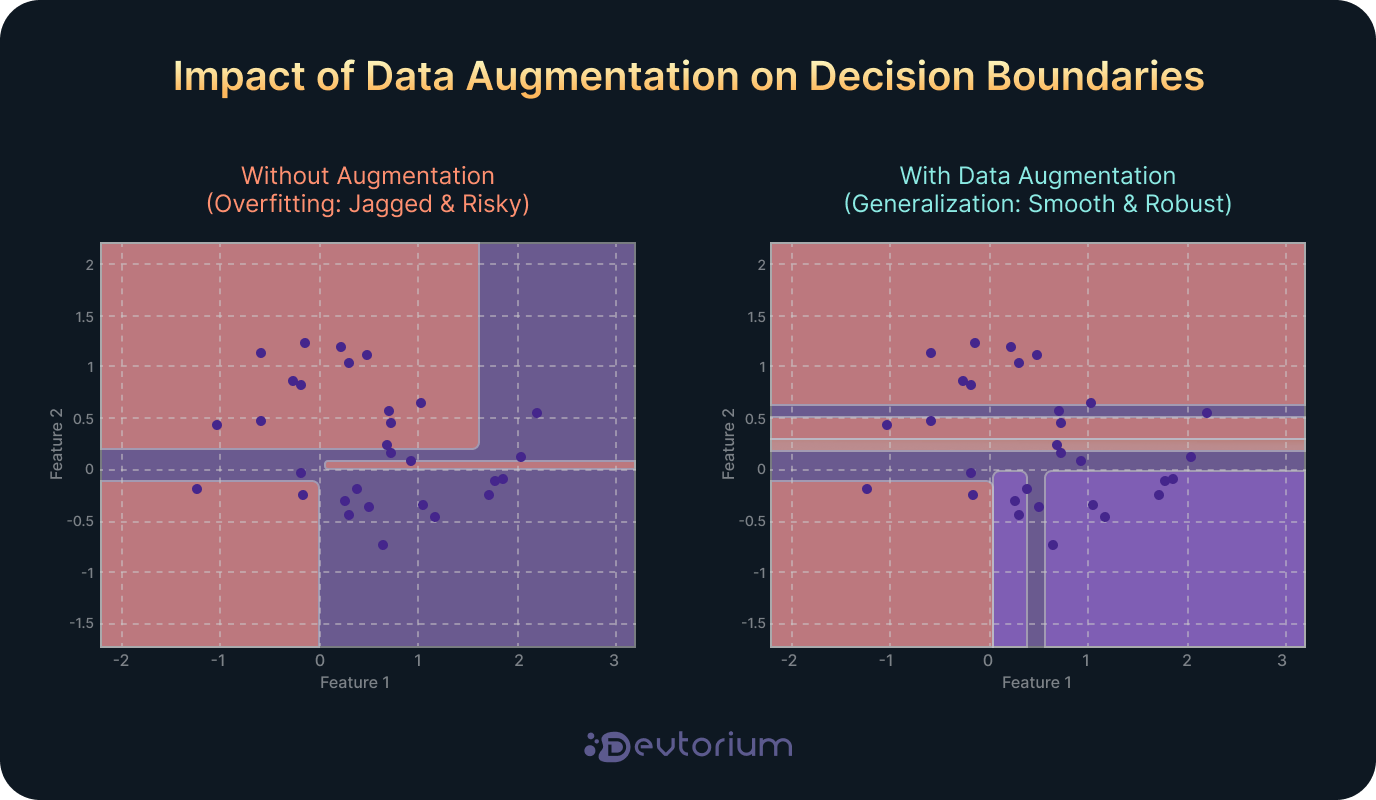
When supported by the right strategies, Small Data can power robust, high-performing solutions in modern software development. Various techniques help compensate for its limitations by introducing additional variability, domain knowledge, or structural enrichment into the training process. One of the most effective approaches in this context is data augmentation.
Data augmentation is a technique that artificially expands a training dataset by creating modified versions of existing data. It works by applying transformations that preserve the data’s original meaning while changing its values. This forces models to learn generalizable patterns rather than memorizing specific examples. As a result, it reduces overfitting and improves model performance on unseen data.
Synthetic Data Generation
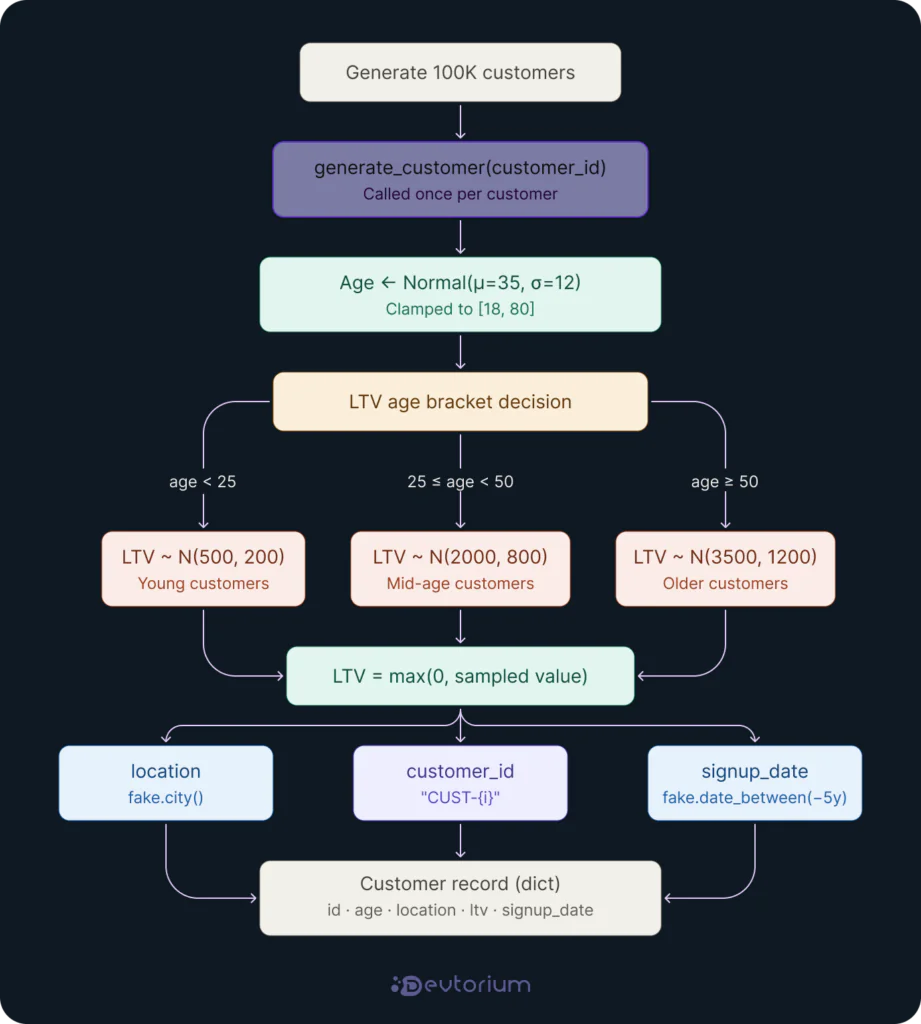
Another way to address the high cost of data and avoid using datasets that do not meet regulatory requirements is to generate synthetic data and use it instead. It is important to clarify that synthetic data is not the same as randomly generated fake data. High-quality synthetic datasets must be validated and verified by human experts to ensure reliability.
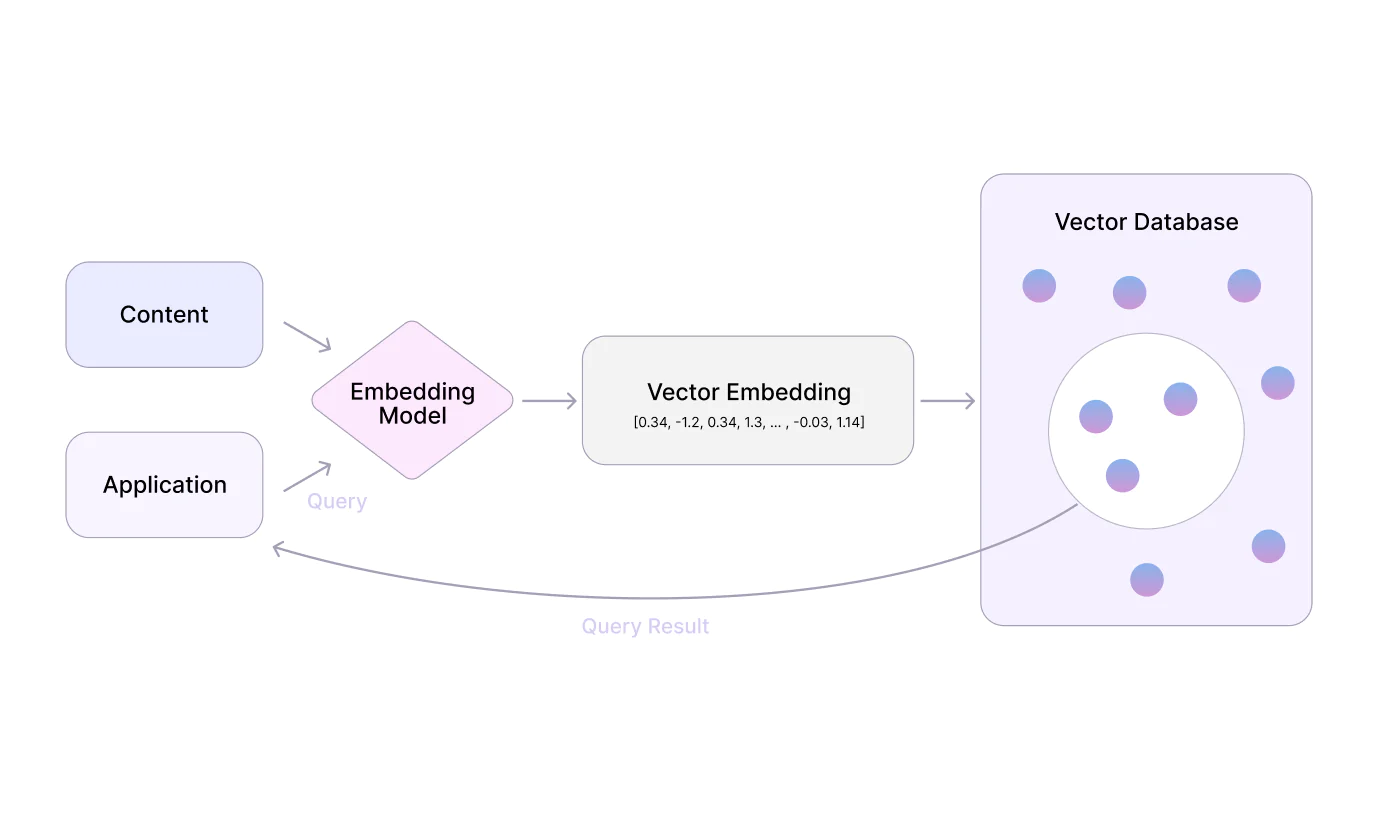
To define it precisely, synthetic data refers to artificially generated data that replicates the statistical properties of real-world data without violating data privacy regulations.
Several approaches are commonly used to generate synthetic data, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and rule-based systems. Below is a brief overview of each:
Generative Adversarial Networks (GANs)
GANs are machine learning models designed to generate realistic data by learning patterns from existing datasets. They consist of two neural networks trained simultaneously in a zero-sum game:
- A generator, which creates synthetic data
- A discriminator, which attempts to distinguish between real and synthetic data
Over time, the generator improves its ability to produce convincing data, while the discriminator becomes better at detecting fakes. This adversarial process continues until the discriminator can no longer reliably differentiate between real and generated data.

Variational Autoencoders (VAEs)
VAEs are generative AI models that compress input data into latent representations and then generate new data samples based on those learned patterns.
Unlike traditional autoencoders, VAEs learn a continuous probabilistic distribution of the data, enabling them to generate new, original samples that closely resemble the input data.

Rule-Based Generation
Rule-based approaches generate synthetic data from scratch using predefined logical rules that replicate real-world constraints and patterns.
Unlike machine learning models that learn from data, rule-based systems are deterministic, relying on explicitly encoded human knowledge and expertise to produce predictable, consistent outputs.
The Synergy: Small Data + Synthetic Data
A combined approach using structured small datasets and synthetic data enhances the effectiveness of developing modern AI or other projects that require specialized data processing.
Small data enables teams to work with carefully curated datasets where each data point contributes meaningful value. When paired with pretrained models (e.g., GPT-3.5 or LLaMA), even limited datasets can yield powerful results through targeted fine-tuning.
Synthetic data complements this by expanding dataset diversity beyond real-world limitations. It allows teams to simulate rare scenarios, balance datasets, and address gaps that small datasets alone cannot.
Together, this cooperation delivers such advantages:
- Higher model accuracy through clean and focused datasets
- Up to 70% reduction in data acquisition costs
- Elimination of privacy and compliance risks (no real user data required)
- 3–5× faster ML development cycles
- Unlimited generation of edge cases not present in real-world data
- Reduced risk of overfitting and knowledge dilution
Conclusion: Business Impact & ROI
The combination of Small Data and synthetic data enables businesses to replace costly and time-consuming Big Data initiatives with high-impact solutions. In practice, organizations can reduce project budgets from ~$200,000 to ~$15,000 by focusing on a limited set of critical metrics and generating near-real training data.
Synthetic data further strengthens ROI by reducing data-related costs by up to 70%, eliminating privacy bottlenecks (e.g., GDPR, HIPAA), and accelerating ML development cycles by 3 to 5 times. It also enables the generation of rare edge cases that are impractical or impossible to collect.
However, this approach has limitations: real data remains essential when large, labeled datasets are already available or when life-critical systems require extensive validation.
Business outcomes:
- Weeks vs. months implementation
- Lower labeling and compliance costs
- Faster experimentation and deployment
- Improved accuracy via relevant signals
Are you looking to turn your AI initiative into a measurable business asset? At Devtorium, we design cost-efficient AI solutions using Small Data and synthetic data. Contact us to evaluate your ROI potential and explore relevant case studies.